When most people think of generative artificial intelligence, they picture something powerful but distant—servers humming in faraway data centers, parsing questions and firing back answers through the cloud. Alibaba Cloud’s latest release takes a different route.
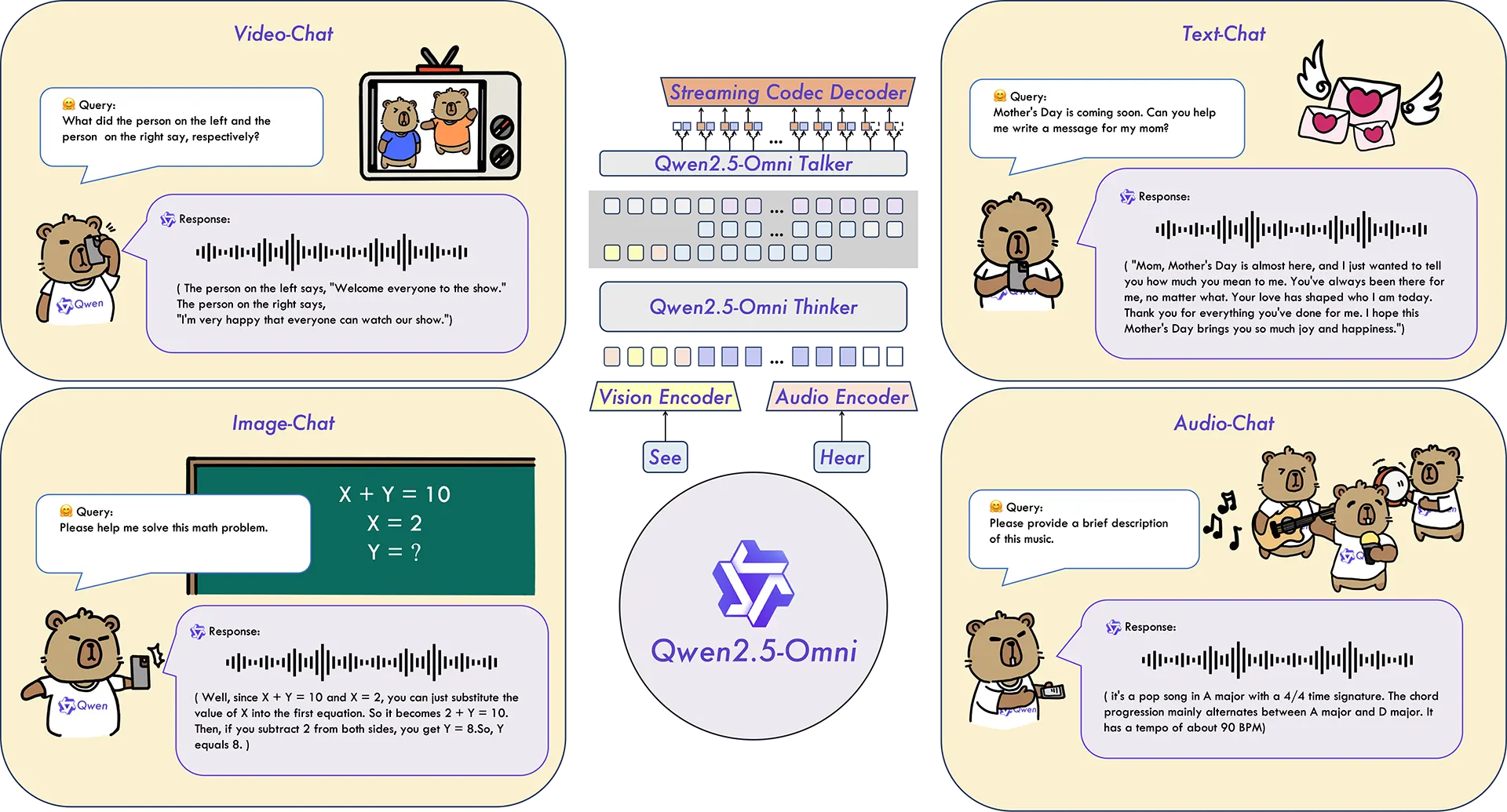
The Chinese tech giant has released a new AI model, Qwen 2.5-Omni-7B, that combines text, image, video, and audio understanding into a compact, deployable system. Comprising 7 billion parameters, the model is part of the company’s Qwen series but is designed to run on edge devices like smartphones, laptops, and other consumer hardware.
Despite its size, Qwen 2.5-Omni-7B functions as a full-spectrum multimodal model. It can process input across four formats and generate real-time responses in both speech and text. The idea is to make it small enough to fit on a phone, but capable of conversing about what it sees and hears.
At the heart of this model is what Alibaba calls the “Thinker-Talker” architecture. The “Thinker” handles language generation, while the “Talker” focuses on producing natural speech. This separation is meant to prevent one mode from interfering with the other, a common issue in multimodal models that juggle too many tasks in a single pipeline.
Other design elements work behind the scenes to improve fluency and timing. A technique called time-aligned multimodal rotary position embedding (TMRoPE) is said to better align video frames with audio timelines, so the model can, for example, describe what’s happening in a video with more accurate timing. Blockwise streaming breaks down long audio inputs and processes them incrementally to maintain responsiveness.
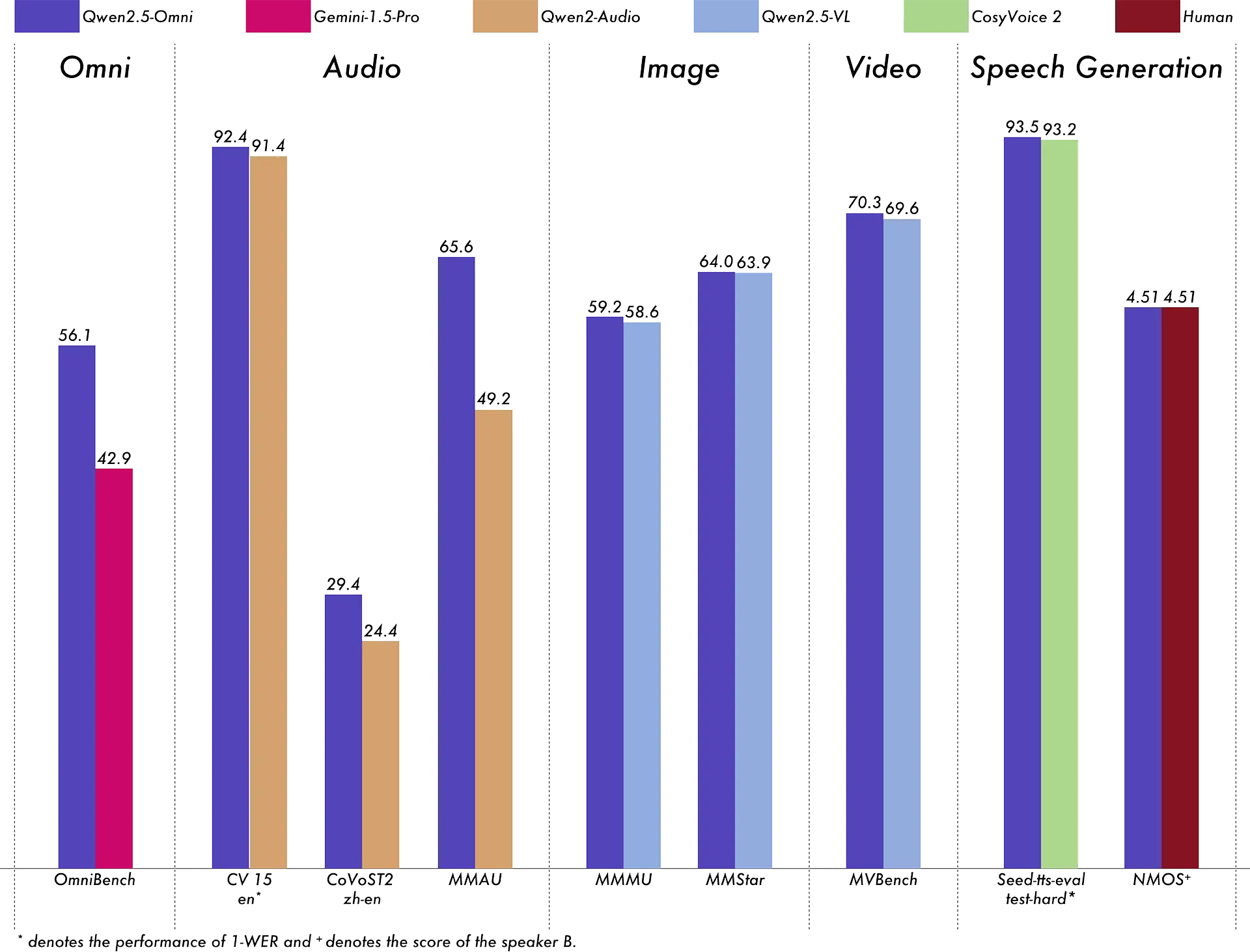
On paper, the result is a model that supports end-to-end use across multiple input types, from voice commands to visual analysis. According to Alibaba, Qwen 2.5-Omni-7B performs well on benchmarks such as OmniBench, which evaluates models’ ability to reason across modalities. It also demonstrates proficiency in in-context learning and shows improvements in voice quality after reinforcement learning tuning—a process that reportedly reduced issues like misalignment, pronunciation errors, and awkward pauses.
Alibaba has pointed to potential use cases that include real-time guidance for visually impaired users, cooking assistants that can interpret ingredients shown on camera, and customer service bots that engage through voice. The throughline is proximity, running sophisticated AI close to the user without having to ping the cloud.
There’s a broader strategy in play too. Alibaba has now open-sourced more than 200 generative models, including Qwen 2.5-VL and Qwen 2.5-1M. The Omni-7B version is available through GitHub, Hugging Face, and Alibaba’s ModelScope platform. These releases build out the Qwen 2.5 line, following the recent debut of Qwen 2.5-Max.
The release reflects a trend among AI developers to optimize for compactness without cutting capability. And embedding real-time multimodal intelligence into an edge-friendly model brings the technology closer to where it’s likely to be used most—on devices in people’s hands.